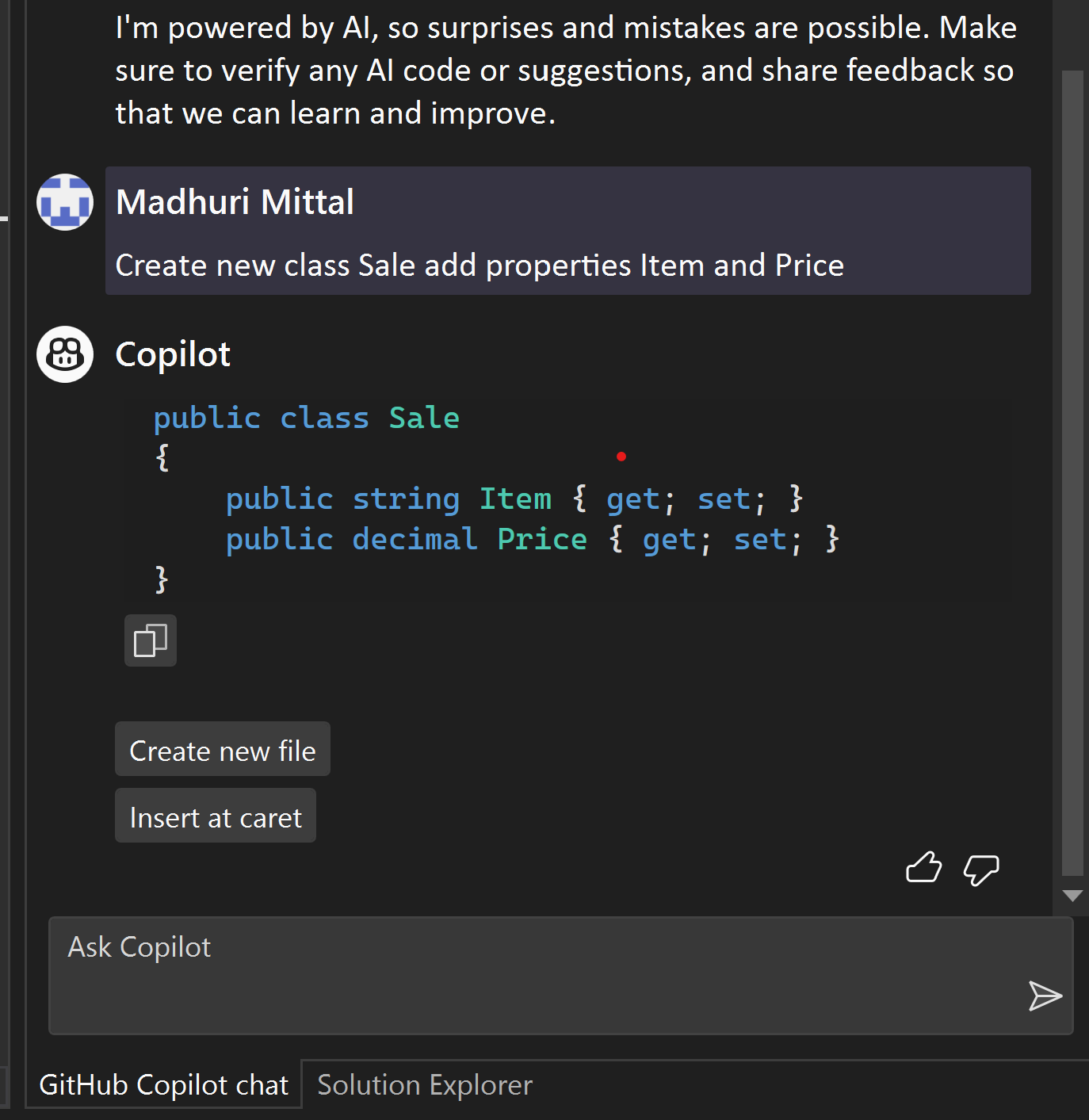
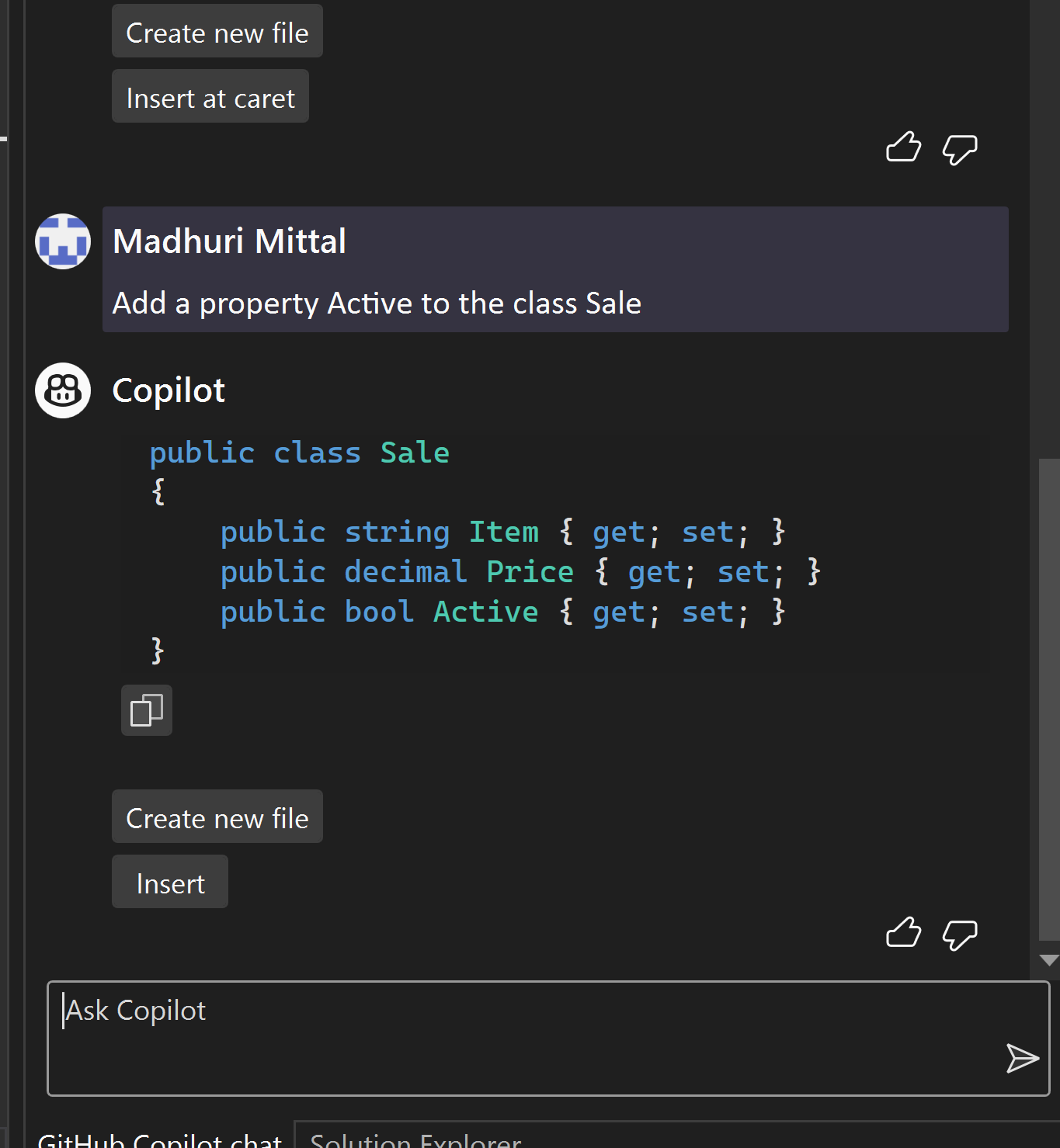
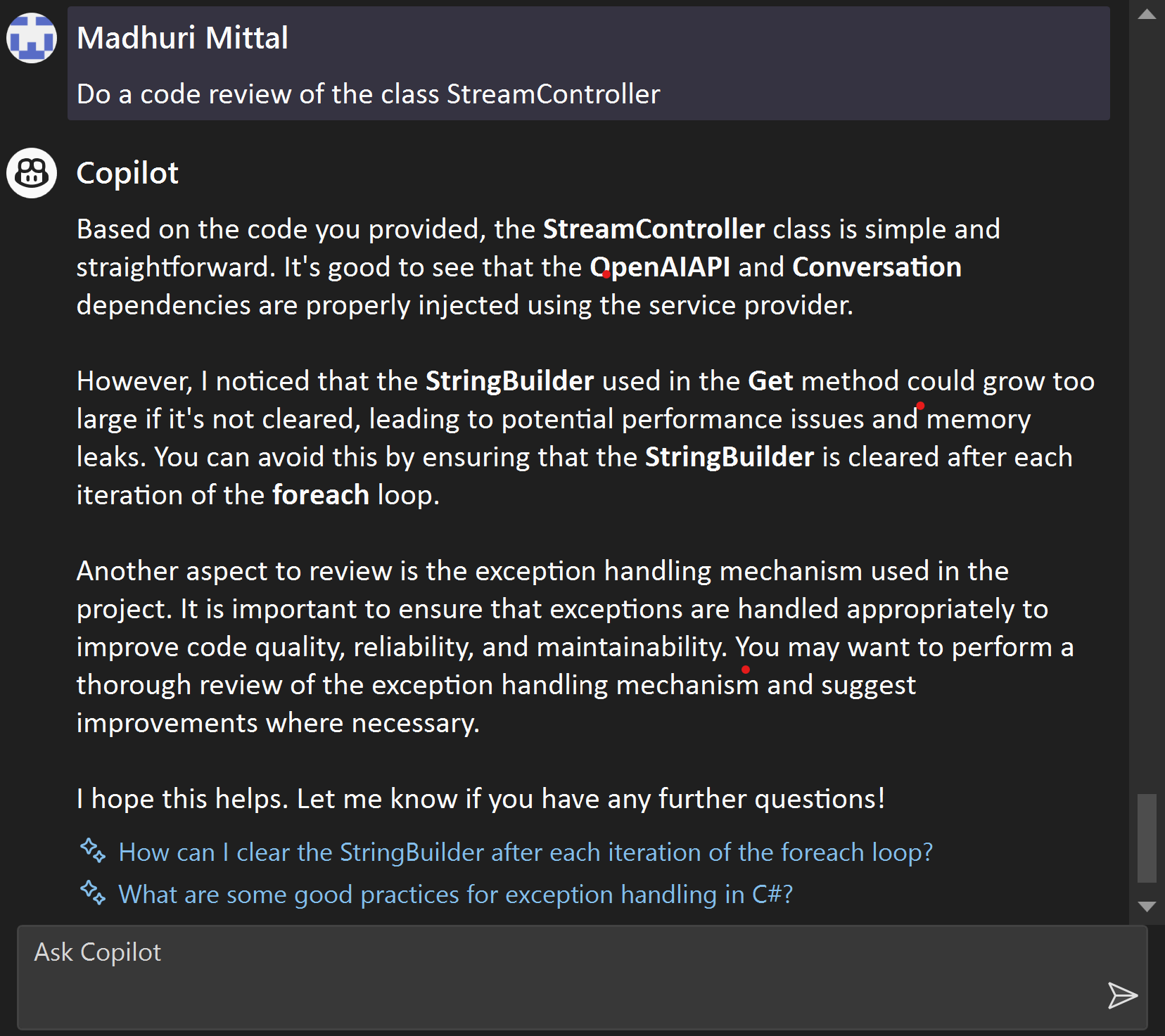
AI-based code generators, like GitHub’s Copilot and various other popular tools, have shown impressive capabilities in assisting developers with coding tasks, intelligently. Previously I wrote an article on how we can use GitHub CoPilot as an AI pair programmer for faster and more effective programming. As we basked in the AI’s potential, skepticism arose. Questions of reliability, security, impact on employment, creativity.
What could be the Pitfalls ?
Code Quality & Reliability: The AI-generated code isn’t perfect and can overlook coding best practices, leading to verbose or inefficient code. There’s also the risk of planting unintended bugs, an inevitable coding nightmare.
Security Threats: Technological advancement brings along potential security vulnerabilities. AI’s code suggestions might fall into this category, and the risk of sensitive data leakage is undeniably a concern.
Skill Erosion: We’re at risk of losing essential coding skills with AI in the driver’s seat. It’s akin to using calculators in math classes, where students may memorize formulas but miss out on understanding the underlying concepts.
Ethical & Licensing Dilemmas: Copyrighted code is an intellectual asset. An AI suggesting a similar line of code raises matters of intellectual property rights, introducing ethical and licensing dilemmas.
Bias: AI is only as good as the data it’s trained on. If the training data carries biases, the AI-produced code might inherit them, causing ethical issues.
Economic Impact: Technological progress has consequences. In this case, the possible reduction in need for entry-level programming jobs, which can impact the tech industry’s employment chart.
Trust & Dependency: A growing dependency on AI might lead to blind trust causing issues in the final product. It’s a case of ‘too much of a good thing.’
Stifled Creativity: Innovation and creativity are yet human realms. AI can’t whip up innovative or off-the-wall solutions. Are we stifling our creativity?
Understanding the Promise
Any modern technology brings both excitement and skepticism in the beginning however as time passes, society often adjusts to its presence, weighing its benefits against its drawbacks, and finding ways to integrate it into everyday life. To understand and verify AI’s promise to modern coding, an experiment and study was conducted by Cornell University in 2022, whose results were published as a paper in Feb 2023:
- Objective: This research focuses on the potential of generative AI tools to boost human productivity.
- Methodology: A controlled experiment was conducted with GitHub Copilot, an AI-assisted programming tool. Developers were tasked with quickly implementing an HTTP server in JavaScript.
Experiment Setup: During the trial, developers were tasked to implement an HTTP server in JavaScript as swiftly as possible. The treatment group had access to GitHub Copilot, and was given a brief introduction video. In contrast, the control group, which didn’t have Copilot access, was unrestricted in other ways (e.g., they could use online search or Stack Overflow).
Any modern technology brings both excitement and skepticism in the beginning however as time passes, society often adjusts to its presence, weighing its benefits against its drawbacks, and finding ways to integrate it into everyday life.
Results:
Those who had access to GitHub Copilot (the treatment group) finished the task 55.8% faster than those who did not (the control group). The performance difference between the two groups was both statistically and practically significant. The confidence interval for this measurement is between 21% and 89%. This means that based on the sample data and the statistical analysis performed, we are reasonably confident that the true performance improvement of the treatment group (with Copilot) over the control group is somewhere between 21% and 89%.
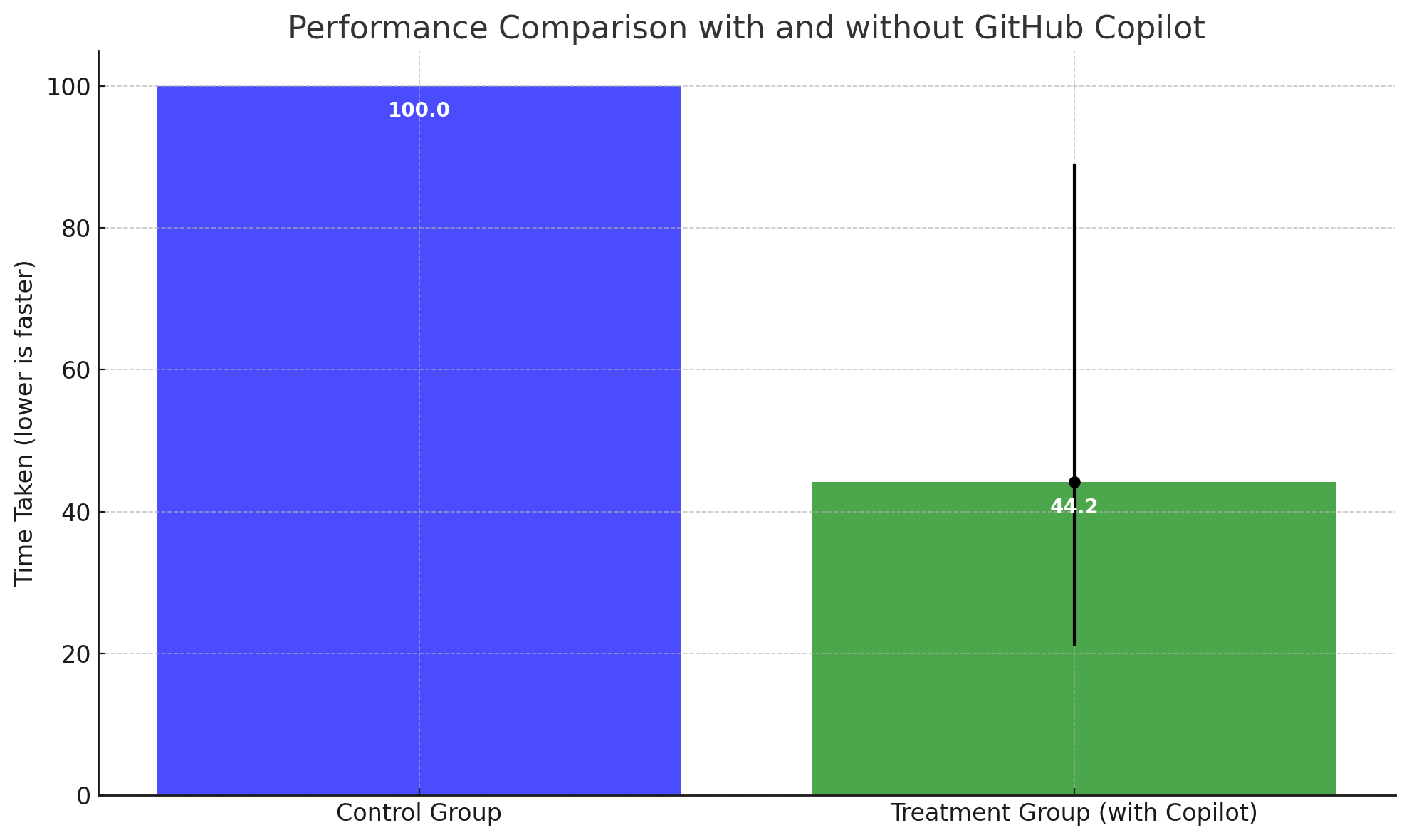
- The blue bar represents the control group, which did not have access to GitHub Copilot.
- The green bar represents the treatment group, which had access to GitHub Copilot. This group finished the task 55.8% faster.
- The black error bar on the green bar represents the confidence interval for the performance improvement, ranging from 21% to 89%.
- If the treatment group was 89% faster, then they would take only 11% of the time the control group took.
- If the treatment group was 21% faster, then they would take 79% of the time the control group took.
Diverse Effects: The AI tool had varied impacts based on developer backgrounds. Those with less programming experience, older developers, and individuals who spend more hours programming daily benefited the most. This suggests that such tools can expand access to software development careers.
Developers with Less Programming Experience (Junior Developers):
- Observation: Junior developers or those with less programming experience derived significant benefits from the tool.
- Implication: GitHub Copilot likely provided these developers with code suggestions and solutions that they might not have been aware of or would have taken longer to derive on their own. This assistance can accelerate their learning curve and increase their efficiency.
Older Developers:
- Observation: Older developers benefited more from the tool compared to their younger counterparts.
- Implication: The reasons for this can be multi-fold. Older developers might have vast experience in programming but may not be as updated with newer frameworks, libraries, or best practices. GitHub Copilot can bridge this gap by suggesting modern code solutions. Alternatively, older developers might be more methodical and take advantage of AI assistance to validate or enhance their code.
Developers Who Program More Hours Per Day:
- Observation: Those who spend more hours programming daily saw more benefits from the tool.
- Implication: Developers who are more engaged in coding tasks can leverage GitHub Copilot more frequently, extracting maximum utility from its suggestions. It could serve as a continuous companion, optimizing their workflow and reducing the time spent on debugging or searching for solutions online.

Other Observations: The paper mentions heterogeneous effects, suggesting there might be varying results based on different conditions or types of developers. There’s also a mention that AI pair programmers might be helpful for individuals transitioning into software development careers.
Affiliations: The authors are affiliated with institutions like Microsoft Research, GitHub Inc., and MIT Sloan School of Management.
Limitations of the study
The research is in its early stages, involving a select group of participants working on a non-commercial project. As such, the product is not designed for public or production deployment. Therefore, concerns regarding licensing, legal implications, and security were not factors considered in this study. Although crafting an HTTP server with JavaScript presents its own challenges, real-world commercial endeavors often encompass intricate systems, necessitating collaboration across diverse teams. In a typical enterprise environment, developers do more than just code solutions for business challenges; they also craft various test cases, from unit to integration tests. Consequently, this study does not evaluate metrics such as code quality or testability.
Harnessing the Potential
Given this brief overview, it seems the study provides empirical evidence for the positive impact of generative AI tools, on developer productivity. The resultant surge in productivity is not merely a metric; it translates to valuable time that can be redirected towards innovative, business-centric endeavors rather than being mired in the repetitive grind of manual coding. While these AI tools aren’t silver bullets for intricate projects, they serve as adept and intelligent CoPilots. For organizations to truly harness this potential, it’s imperative for leadership and engineering heads to foster a culture of vigilant oversight, continuous training, and rigorous code reviews. This proactive approach can not only maximize the advantages of these tools but also address the challenges highlighted earlier in the discussion.
Happy programming !
Resources
Here is a link to the study paper available on the web:
Cornell study: Impact of AI tools on Developer productivity
Please note there is a link to the downloadable PDF at the right hand top.